
Looking at Working Memory Another Way
A pyramid model approach to Cowan's Embedded Processes Model


Thank you everyone who read my previous post, my first on Substack, and those who subscribed or followed. You are making the effort worthwhile.
In that previous post, I laid out my three-part answer to the question of why cognitive science is important to educators. Here, I look at Working Memory through the same triple lens: functions and limitations, the phases of the learning process, and the fact that we need to learn how we learn. I will share another way to understand Working Memory, one that integrates functions and limitations with the phases of learning and helps us see a complex picture through a concrete analogy.
Fortunately, Working Memory (WM) has become a familiar concept in education. It is also an area with substantial translational research, notably the effects described by Cognitive Load Theory (e.g., this report) and the principles outlined in Mayer’s Theory of Multimedia Learning (e.g., Mayer 2021, or this page). Together, these have shaped how we understand and apply evidence about WM. This makes it a good moment to look at the basics in a somewhat different way.
Working Memory can be described simply as a limited-capacity mental space where we actively and temporarily manipulate information. Its most recognised features are the limited capacity and the resulting experience of cognitive load. Yet neither is the core feature. The central function is what the system works on - building knowledge and making memories. Capacity limitations may be easy to demonstrate, but in practice, WM performance is dynamic. It changes considerably depending on the learning context, the stimuli, our relevant prior knowledge, and how these elements interact. Therefore, the familiar rule of thumb to “reduce cognitive load” may be simple and actionable, but it can also obscure the key idea.
In this post, I explore how the way we model WM influences how we understand and apply it. I suggest a less common angle that accounts for complexity without becoming overly complicated. As some of you may know, I find graphical models very useful for teaching and thinking about learning from a cognitive perspective. These models, designed for this purpose, serve as a concrete thinking and planning space that allows us to see both the whole picture and its individual elements. For some time, I have been wondering about how to visually represent WM more effectively, and this is my attempt to do so.
To build toward this angle, I will go through several steps:
What do we know about working memory?
What models exist in the scientific literature? Are they helpful for educators?
How can we draw a visual model of memory using a concrete analogy (pyramids)?
As a final step, I will bring these together to represent and visualise working memory as an interaction between incoming stimuli and prior knowledge. If you feel ready, you can jump directly to the last section below.
What do we know about working memory?
Have you ever participated in a short working memory demonstration, the kind where you are asked to remember a sequence of digits, letters, or words that is briefly presented (like this one)? I do them quite often, and the experience is usually something like the following:
Remembering a sequence such as [4 6 2 5] is fairly easy.
A sequence of six digits such as [9 1 8 3 4 8] is more difficult but still manageable. Any sequence longer than eight or nine digits becomes challenging or even impossible if it is random and unfamiliar.
A sequence of symbols like [⍾ ⎄ ⎅ ⎋ ⍝] is very difficult to reproduce, even though it contains only five symbols.
And this sequence [1 2 2 3 3 3 4 4 4 4 5 5 5 5 5] is much easier, even though it is much longer (fifteen digits!)
In my experience, this pattern is remarkably consistent across dozens of classrooms, with children, teens, and adults alike. It demonstrates several well-established features of working memory:
Functional capacity is limited to an average of about seven familiar symbols, such as digits, letters, or words, but only two to four unfamiliar ones.
Distractions reduce processing capacity. They either occupy some of the limited attentional slots or divert attention altogether.
Despite its limited capacity, performance varies widely depending on the nature of the stimuli and the amount of relevant prior knowledge available.
The most effective strategies for improving performance rely on knowledge stored in long-term memory and align with how memory works, such as meaning-making, visual imagery, and spatial organisation (see this classic video for example).
Not in the demo, but often asked: Are there ways to increase WM capacity? Apart from the gradual increase that occurs during development, it remains fairly stable. Capacity varies slightly between individuals, and this variation correlates with cognitive performance. However, there is no evidence that the basic capacity itself can be increased through training.
WM capacity is therefore a stable feature that strongly influences cognitive performance. Yet while the limitation is easy to demonstrate, it is difficult to predict in practice because performance depends on what a person already knows about the incoming stimuli and how the interaction unfolds.
While we cannot increase capacity through training, we can manage the process effectively through instruction and effective strategies. To do that well, it’s best to have a clear picture of how the system truly works as a basis.
Effective models can help us do so, provided they are simple enough and capture the essence of cognitive function vividly.
How can models from cognitive science help us understand the workings of working memory for educational purposes?
Working Memory Models
There is also much we do not yet know about working memory. For example, why is its capacity limited? How does WM actually work in the brain? How many subunits are involved, and how are they coordinated? Another open question concerns how different forms of information, such as text and images, are processed together, and under what conditions they interfere or rather support each other.
Over the last half-century, cognitive scientists have worked to address many of these questions by developing models that represent their findings and generate new hypotheses. This work is still ongoing.
George Box is famous for the quote, “All models are wrong, but some are useful.” In this sense, current WM models may be inaccurate, but they still advance cognitive research. The question here, however, is different:
Are they useful for translating scientific evidence into better instructional practice? Let us briefly explore:
The Simple Model
The simple “textbook” model depicts the major elements of information processing: perception, attention, working memory, and long-term memory. It is based on the early multi-store model proposed by Atkinson and Shiffrin in 1968. In the original model, the component was called Short-Term Memory rather than Working Memory, but the basic mechanics of the model are still widely used today.
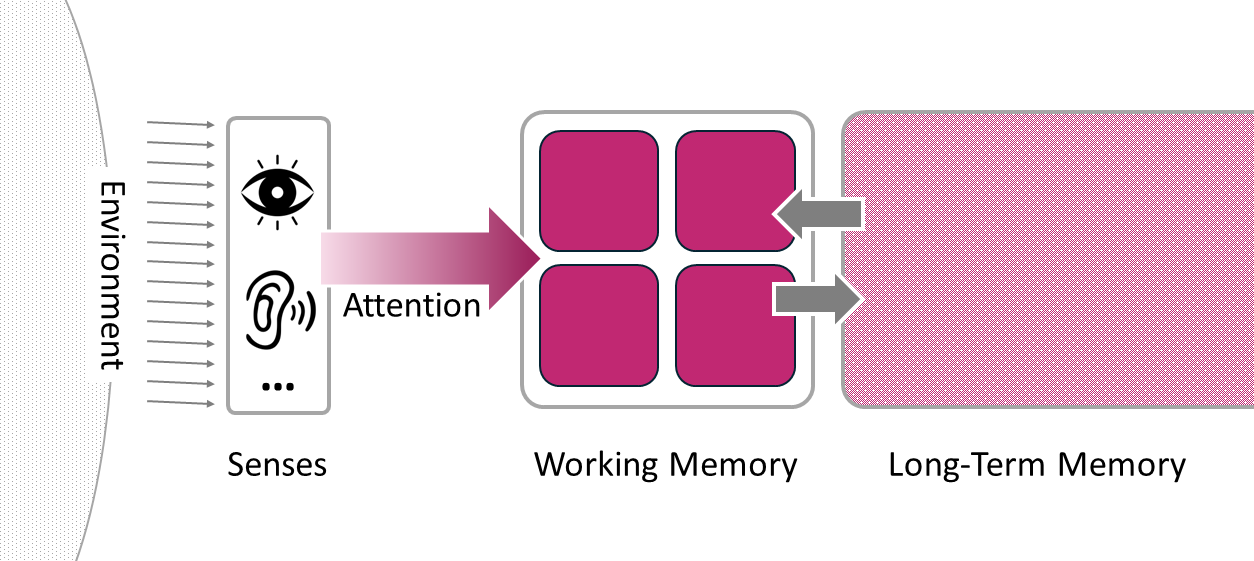
The model presents information processing as a linear sequence that resembles a conveyor belt in a factory, where designated ‘machines’ operate along the line. Working memory and long-term memory appear as separate stores with bidirectional arrows between them representing encoding and retrieval. The “product” supposedly moves between these stores.
This model is straightforward. Its simplicity makes it easy to understand and easy to share. It allows discussion of each cognitive function separately, along with its features and limitations (e.g. WM is limited, LTM is unlimited). Thanks to this model, many of us today know what working memory is and recognise its limited capacity as an important constraint.
I use this model frequently in introductory sessions for exactly these purposes. Yet while it is useful, it often does not feel quite right pedagogically. I find it a cumbersome way to discuss the crucial workings of memory - the binding between new information and prior knowledge - which the model itself does not represent.
Multi-Component Models
Scientists have developed more advanced models based on this simple one. The most prominent is Baddeley and Hitch’s multicomponent model, first published in 1974 and still evolving more than fifty years later (Hitch et al., 2025). This model extends the single short-term memory store into several working- memory subcomponents coordinated by a central executive (image here).
While very useful for research, it is probably too complex for translational purposes. In addition, the aspects it explains are not necessarily those I was looking for in the earlier one.
Another extension of the multi-store framework is in Mayer’s Theory of Multimedia Learning. This model highlights organisation and integration as part of the Select- Organise-Integrate framework, which is why it is useful from an instructional perspective. However, these processes are not visually represented, and the model still relies on the separate stores configuration
The Embedded Processes model
Another prominent model is Cowan’s Embedded Processes Model (Cowan, 2019, 2024). While it shares some features with earlier models, it takes a different approach. It departs from the idea of separate stores and presents a more dynamic and integrated view of how memory works. In this model, working memory is not a separate store but a function that arises from interactions between incoming stimuli and activated portions of long-term memory within the focus of attention. Rather than information moving between stores, new and existing representations are activated simultaneously and can bind together. As attention shifts, the new construct remains briefly in activated but unattended long-term memory before becoming inactive. Binding during this activated state may later lead to consolidation and storage. According to this model, WM limitations arise from the limited capacity of attention, about three to five items, and from the limited duration of long-term memory activation, typically less than one minute (see Fig. 1 in Cowan et al., 2024).
I find this model more parsimonious and elegant because it focuses on the core interaction while still acknowledging the limiting factors. Although it may take some time to adapt to this perspective, it appears to be a useful model for thinking about learning in educational contexts.
Illustrating the Model
If you do not see it clearly yet, you are not alone. We need a more tangible way to think about it clearly. After all, this is how we learn.
This was also the goal in the first place - come up with an effective way to model working memory: accurate, yet not too complicated. It’s time to test this idea - to illustrate the embedded processes model.
In a previous short blog, I used the network model of memory representations to do so. Here I share an attempt to represent it using the pyramid model of knowledge construction. I will briefly introduce the pyramid analogy and then use it to explore working memory through the lens of the Embedded Processes Model.
The Pyramid Model of Knowledge Construction
The pyramid model is an illustration designed to support understanding and discussion of learning and memory. It provides a concrete analogy for constructing our knowledge base. Triangular blocks represent ideas or concepts, which are used to build larger and more complex pyramids representing conceptual “chunks.” A new word or concept, for example, ‘retrieval’, may begin as a single block at first exposure. When it is meaningfully connected to existing knowledge and then practised repeatedly, it becomes more useful and gains deeper meaning, represented by a larger and cemented pyramid.
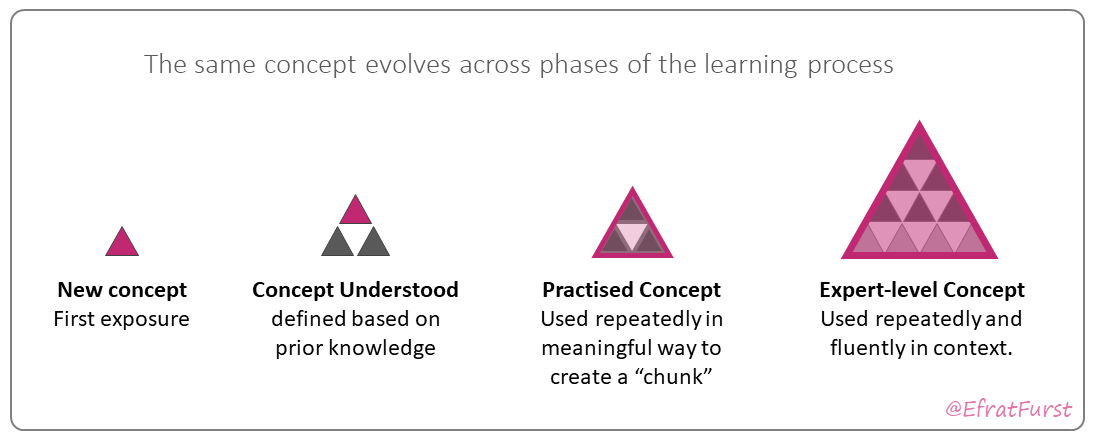
There are three main analogies here:
New ideas always build on existing ones. A new block “lands” on an existing knowledge base.
Creating a pyramid shape represents ‘meaning making’ - each block can “land” in different places, but when it stacks correctly on relevant prior knowledge and forms a new pyramid, it makes sense!
Cementing a new structure into a single new, larger pyramid is the result of effective practice. When we practice and construct the same pyramid repeatedly, its pieces become cemented into a new whole. We can then use this structure as a single unit and build further. This is crucial because chunked pyramids allow us to hold more information in working memory, while using the same number of “slots”.
This process of building on prior knowledge, making meaning, and practising toward fluency continues iteratively as we gain more knowledge and experience.
Putting it all Together: How Working Memory Works?
Finally, this is how I imagine how memory works, as inspired by Cowan’s Embedded Processes Model and illustrated with pyramids (and hooks):
Our existing body of knowledge stored in long-term memory (LTM) can be represented as a huge structure of pyramids, forming many interconnected structures of different sizes. At any given moment, most of this structure is inactive. When something happens around us, for example, when we read or hear new words, our attention focuses on them, that is, on their mental representations. Several items become “hooked,” filling the available attentional slots. At the same time, related portions of our existing structures become activated. The key question is what kind of activation and binding will occur among these “working” elements, because this binding can lead to memory consolidation and later storage in LTM.
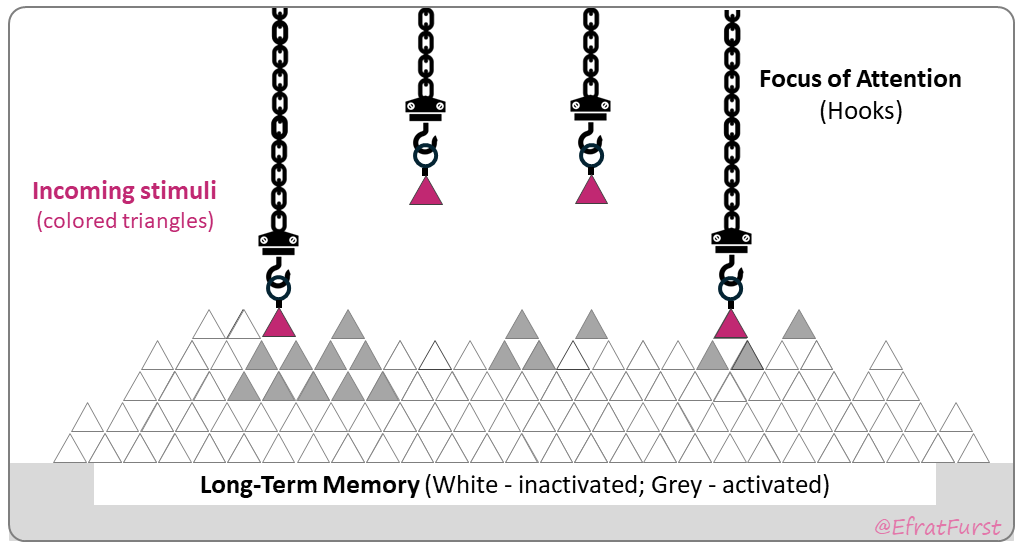
The goal is to visualise the extent to which these hooked elements can bind to existing structures, and what structure may remain once the hooks disappear.
To illustrate this idea, consider a simple example. Imagine a task in which you are asked to remember four words after they are briefly presented, similar to the digit span task above.
The words are:
Testing
Spacing
Interleaving
Variation
Will you remember them after a minute? An hour? A day? A week?
The answer depends on what you already know. We know this intuitively. But can we see it?
Let us explore three different cases.
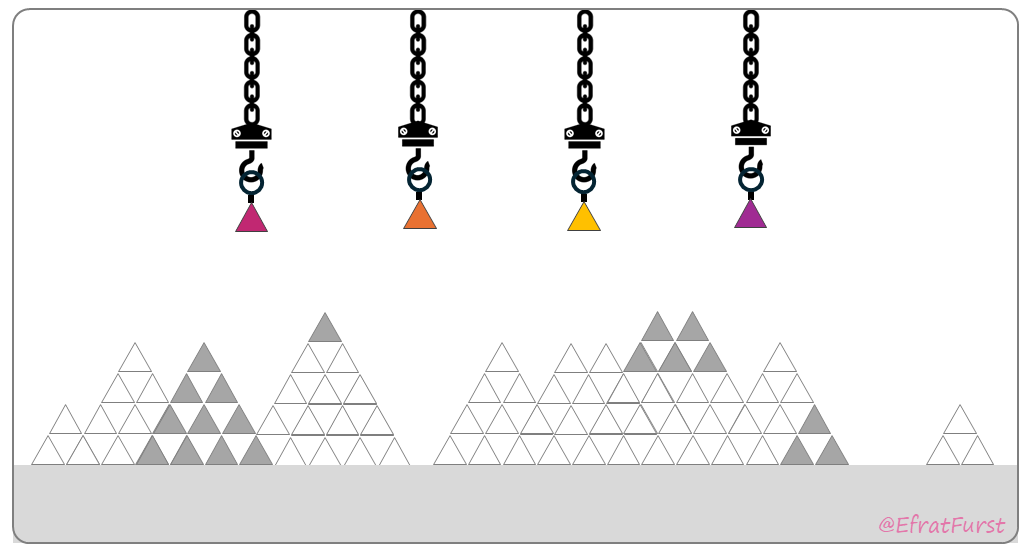
Case 1:
These four words are completely new, and you see them for the first time ever! The words themselves, represented as four colourful triangles, occupy the available capacity, the hooks. Because there is little to no relevant prior knowledge, the activated portions of LTM are randomly scattered and unconnected to the new items. The chances for meaningful binding are therefore low, and the activity is unlikely to leave a trace after attention fades.
Case 2:
These four words are familiar, and their meanings are known. However, they have not been learned within a shared conceptual context. They remain four unrelated words with no clear semantic connection. In this case, they may activate small structures representing their individual meanings. Some associations may emerge, but they are local and random, so remembering the words later is still unlikely (assuming no strategy is applied).
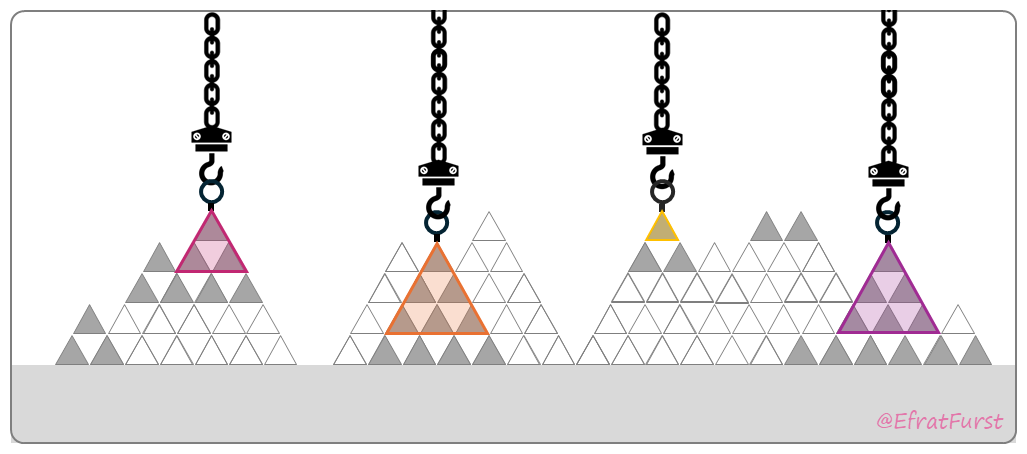
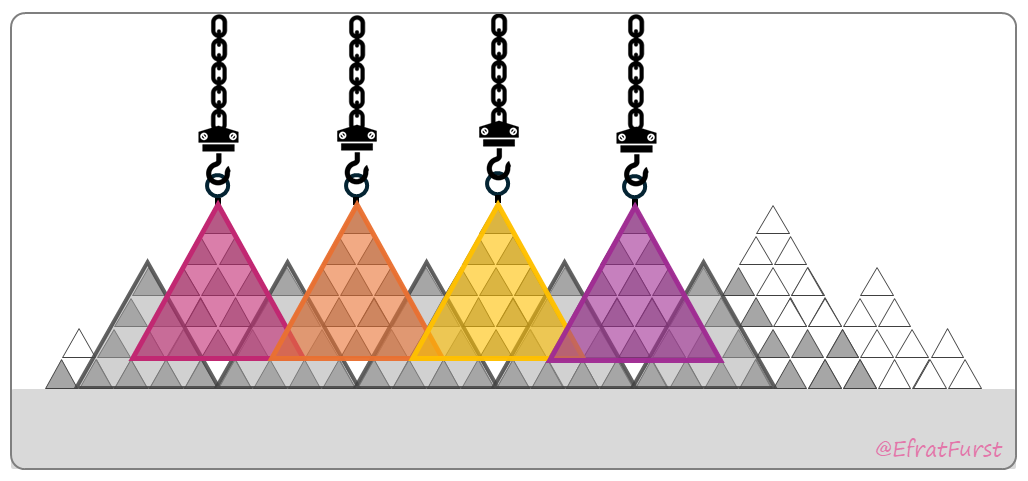
Case 3:
These four words are not only understood but also well rehearsed within a specific context - cognitive science. In this context, they represent strategies that are categorised as Desirable Difficulties, actions that make practice more difficult in a productive way, as described by Bjork (e.g. in this video). They are also closely connected with related concepts such as practice, transfer, fluency, and feedback, and are used regularly in professional contexts.
In this situation, the four words are part of a well-developed expert network. Each word activates not only a single chunk, represented by a larger cemented triangle, but also a broader network of related concepts. The same four hooks, therefore, trigger an entire interconnected structure - an iceberg of ideas. Binding becomes meaningful and strong, and the chances of reconstructing these words later are much higher. (In this situation, false retrieval of words that were not actually presented, like ‘retrieval’, is also very likely).
By the way, can you still reconstruct the fifteen-digit sequence from the first section? And the shorter ones? Can you see the difference?
These three cases illustrate how identical surface conditions, four stimuli and four attentional hooks, can produce very different outcomes. The crucial factors are the structure that already exists in long-term memory and the types of interaction.
Final thoughts
Viewed this way, working memory justifies its name: it’s memory at work. It's a function, not a store. The key mechanism is the simultaneous activation of incoming stimuli and existing knowledge structures, which together shape the potential for later memory and performance. The focus, therefore, shifts from the capacity limitation and cognitive load to the interaction between new ideas and prior knowledge. What we should manage through instruction is not just the number, but critically the shape - and this is something I think is worth having in front of our eyes.
This perspective also allows us to imagine additional instructional situations:
What does intentional activation of prior knowledge look like?
How do concrete examples support learning?
Why are single exposures rarely enough, and why is repeated practice necessary?
Why do experts and novices learn so differntly?
among others…
Concrete models, even if simplified and imperfect, help us plan teaching sequences and make professional decisions about instructional strategies. They provide a conceptual framework that supports thinking and planning. For this reason, it matters which model we choose and which concrete analogies guide our thinking.
This model is admittedly more complex and more challenging to teach, and that is an important consideration. It is probably wise to begin with the simple model when introducing the basic functions and limitations of memory. But since I believe that cognitive science should inform professional decision-making, I cannot help thinking about how to teach these ideas effectively.
This pyramid-based representation is my attempt to develop such an approach for working memory, and I plan to keep testing and refining it. If you have thoughts and insights to share, I would be very glad to read them.
References:
Centre for Education Statistics and Evaluation. (2017). Cognitive load theory: Research that teachers really need to understand. NSW Department of Education.
Mayer’s Principles of Multimedia Learning, Educational Technology by Serhat Kurt
Mayer, R. E. (2021). Evidence-based principles for how to design effective instructional videos. Journal of Applied Research in Memory and Cognition, 10(2), 229-240.
Introduction to Working Memory, Centre for Neuroscience in Education, University of Cambridge
Atkinson, Richard C., and Richard M. Shiffrin. "Human memory: A proposed system and its control processes." Psychology of learning and motivation. Vol. 2. Academic press, 1968. 89-195.
Hitch, G. J., Allen, R. J., & Baddeley, A. D. (2025). The multicomponent model of working memory fifty years on. Quarterly Journal of Experimental Psychology, 78(2), 222-239.
Cowan, N. (2014). Working memory underpins cognitive development, learning, and education. Educational psychology review, 26(2), 197-223.
Cowan, N. (2019) Short-term memory based on activated long-term memory: A review in response to Norris (2017). - a response to the "Stores" view:
Cowan, N., Bao, C., Bishop-Chrzanowski, B. M., Costa, A. N., Greene, N. R., Guitard, D., Lee C., Muzich, N.L. & Ünal, Z. E. (2024). The relation between attention and memory. Annual review of psychology, 75(1), 183-214.
It seems that the new model that is being proposed is more aligned with the assumptions of ecological psychology view of cognition rather than the view of classical cognitive psychology. I wonder do you think the debates between different paradigm also help shape our understanding of concepts, including working memory?
https://complexity-methods.github.io/book/component--vs.-interaction-dominant-dynamics.html
"(In this situation, false retrieval of words that were not actually presented, like ‘retrieval’, is also very likely)."
I literally made this exact error when deciding to test myself, and then I continued reading and found you'd predicted it.
Astonishing post.